

Precision & Recall
Two fundamental product concepts that, once you know, you'll see everywhere

TL;DR:
“Precision” is a measure of the accuracy of a detection system. Improving precision is to reduce your false positive rate.
“Recall” is a measure of the coverage of a detection system. Improving recall is to reduce your false negative rate.
When I joined the Integrity team at Meta in 2018 (often known elsewhere as “trust and safety”) I’d come from ~3 years building enterprise communication products. I had a LOT to learn, and fast.
Two words I kept hearing a lot were “precision” and “recall” - which, at the time, I didn’t understand. Googling resulting in lot of hits about search result pages. What did that have do to with keeping people safe online and upholding our Community Standards?
Luckily, we had a badass PM, Eng, and DS team who gave me a crash course — and the goal of this post is to be the article I wish I could have sent myself back in 2018 when I realised these were concepts I needed to understand fully, and fast.
Once you know what precision and recall are, you’ll see them everywhere. Policymaking? Policing strategies? Netflix recommendations? Digital marketing? Kids birthday party invites? All precision & recall problems. Seriously.
Let’s imagine you want to find all the “bad stuff” on your website that lets people upload their own content. Let’s also assume we have some definition of “bad” that’s been lovingly crafted by your policy team (or perhaps imposed by your local government).
Sadly, there’s no checkbox when people upload new content that says “this is spam” or “this is a fake account” — so you have to go find it yourself.
But even if you could magically scan through everything being uploaded now and everything that’s ever been uploaded in the past (extremely non-trivial), then how do you actually determine what is good and bad?
While some nudity, for example, is clearly sexual in nature (let’s assume that’s in the “bad” camp). But what about people’s beach holiday snaps where there’s perhaps a lot of flesh on show? Visible male nipples may be OK, but female nipples may not be — but what about someone breastfeeding? or men with gynecomastia? Or people in gender transition? Or things that look like boobs but aren’t. Context matters.
It’s tempting to think of detection systems as binary — but nearly all are actually probabilistic. When a detection system looks like it’s giving a binary output (bad or not bad) then what’s likely happening behind the scenes is that someone has picked a threshold above which we say “bad” and below which we say “good”.
This gives rise to two very important properties.
what is predicted (or detected) as good or bad - as determined by a detection system that can operate at scale (e.g. automation, human reviewers etc)
what is actually good or bad — as determined by some expert analysis (“ground truth” e.g. a trained professional or a court of law).
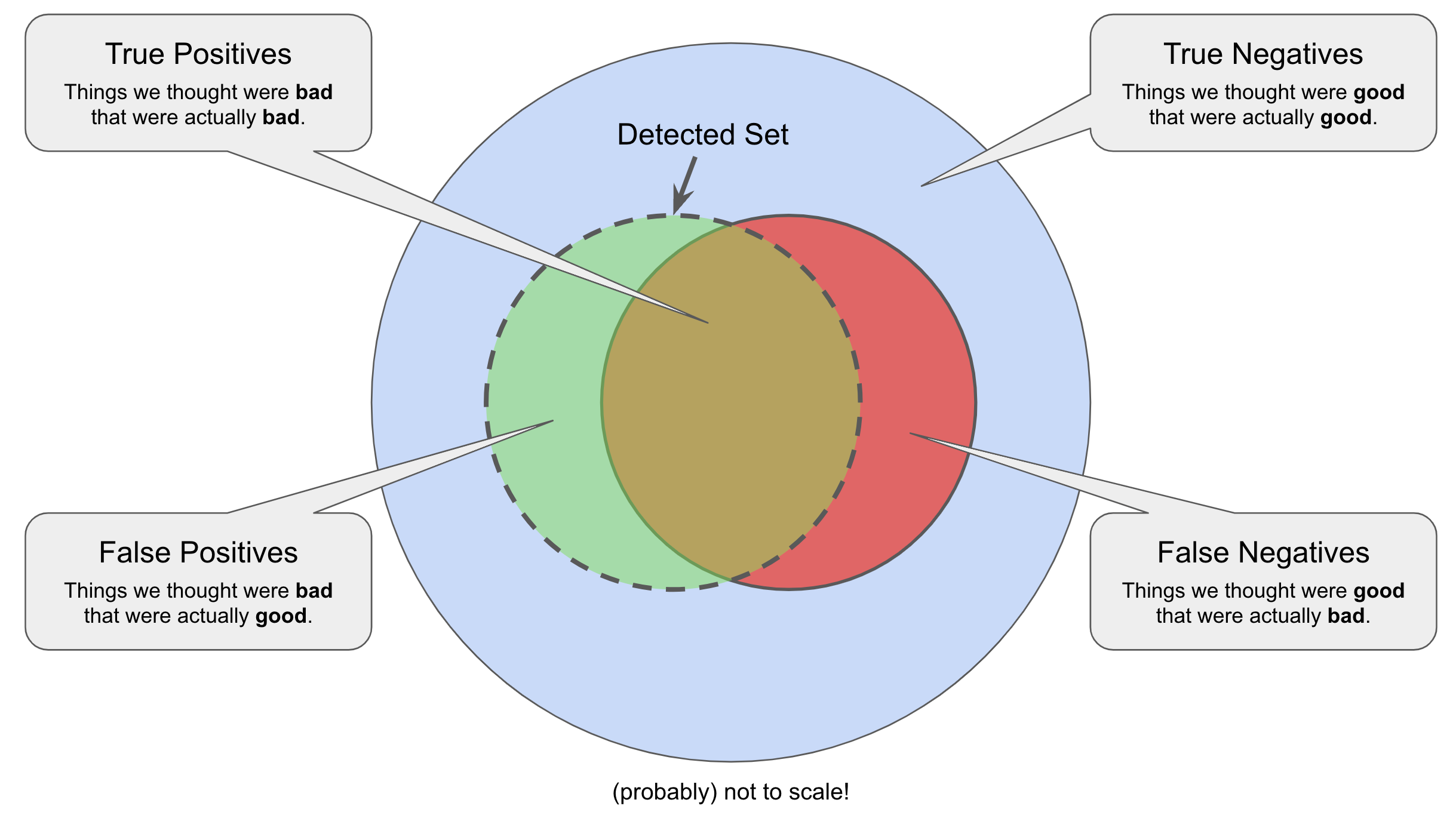
This leads us to something known as “the confusion matrix”. It’s called that for good reason because it messes with your head — but stare at it enough and eventually it will click:

In the ideal state you want to be in a state such that:
Everything you detect is bad (high true positives, low false positives) → we call this precision.
You detect all the bad stuff (high true positives, low false negatives) → we call this recall.
Let’s use an example:

In this example, our system has detected 9 items, 8 of which, upon deeper evaluation are actually bad, and 1 of which is actually good (or more properly, “not bad”). This rogue item is a false positive (something we detected as bad that was not actually bad). This gives us a precision of 88% - not too shabby. Still, that one person that got (for example) their Twitter account disabled is gonna be, understandably, super pissed.
But look, we missed a TON of bad stuff — 12 bad things are still out there. This means our recall was only 40%. For every bad thing we take down, there’s on average nearly another that we didn’t find.
So lets try and capture more of the bad stuff by re-tuning our detection system to be more “sensitive”…

Yay, we’ve now detected all the bad stuff (recall is 100%), but at what cost? Our system now thinks 30 items are bad, but only 20 actually are — the other 10 are false positives. That means for every two bits of, say, hate speech we’re detecting and taking down, we’re taking down one bit of legitimate speech (precision 66%). Not awesome for freedom of expression. Is that the right tradeoff? Depends on your point of view.
While it may be temping to view things as both binary (good or bad) and always accurate (detected good = actually good, detected bad = actually bad) — in reality, things are much more complex.
The unary concept of “accurate” doesn’t even cover it — to describe these systems properly we need the twin concepts of precision and recall.
Now that we’ve clearly explained these two concepts you’ll see them everywhere…
Fire alarms — you want them to go off when there’s a fire (recall) but only when there’s a fire (precision).
Fraud detection — you want to block all fraudulent transactions (recall) but not block legitimate payments (precision).
Party invites — you want to ensure all the fun people are there (recall) and all the people there are fun (precision).
Trading off precision and recall
While the ideal state for any detection system is high precision (no false positives) and high recall (no false negatives) this is impossible to achieve in practice.
As the designer of a detection system, one of your critical tasks is to pick an operating point — set the parameters and thresholds of your system that are reasonable for your particular use case. But this always means trading off precision and recall.
To make and informed choice about this, we can plot the “precision-recall curve” of our detection system on a chart:

Note: creating a chart like this isn’t trivial either — you need to take your detection system, and have it run over a set or known-bad and known-good items at a variety of thresholds.
To understand this chart, lets pick a couple of points at the extremes of the curve:

At point #1, we have a precision of ~98%, but a recall of only 10%. That means when our detection system trips, it’s right 98% of the time — but still wrong 2% of the time. But we’re only catching 1/10th of the bad stuff. For every one bad things we find, there are 9 still out there!
At point #2, we have a recall of ~95%, but a precision of only 30% — so for every one bad thing we detect, we’re detecting 2 good things.
Neither of these extremes is likely acceptable; but the appropriate point on the curve depends on the problem you’re solving, and your point of view.
In general terms, high-recall low-precision is favoured when the cost of acting is low, but the cost of not-acting is high. And vice versa.
Examples that favour precision over recall:
Justice systems: the principle of “innocent until proven guilty” along with the requirement for majority (sometimes unanimous) jury verdicts aims to minimise the number of mis-convictions. But this is at the cost of recall — someone who did indeed commit the crime may “get off” due to lack of evidence (false negative), which is deeply frustrating to victims. But this is generally because the penalties courts administer can be severe (loss of liberty, death) so there’s a desire to keep precision high to ensure punishment remains legitimate.
Social media moderation: Social media allows people to express themselves online - sharing things with family and friends, or publicly. Freedom of expression is something people expect in real life and thus they expect that in their digital communication tools. When people feel their speech is being unduly impinged upon, it can cause deep resentment and anger. More broadly, there are, let’s say, historical examples of why censorship is problematic. As such, most social media companies generally hold a high bar for precision, at the cost of some recall. Some may see this as unacceptable (“you’re letting all this bad stuff happen!”) but if they could see the precision-recall curves, perhaps those critics would be more aghast at the freedom-of-expression implications of operating at a different point on the curve.
Examples that favour recall over precision:
Fire alarms: A fire alarm that doesn’t alert you of a fire is not much use. While false alarms might be annoying, they’re far less annoying than dying. Fire alarms thus normally favour recall (go off even when you burn some toast) over precision (where there’s smoke, there’s not always fire).
Initial cancer detection: Successful treatment of cancer is dramatically more likely if detected early. Doctors will therefore likely order diagnostic tests when they’re even slightly worried a patient may have cancer. While these follow up tests (biopsies etc) are high-precision and high-recall, the cost of these tests is low, but the cost of missing cancer early is high (dramatically lower survival rates).
Key task #1 - Pick the operating point
Given a system with given precision-recall properties, someone needs to pick the threshold at which it operates.
This isn’t often a technical job — it’s one of POLICY. What’s the right balance of FPs to FNs? What is acceptable to your stakeholders? How do you defend your choices? Policy folks, of course, would rather not have to make this decision because engineering have devised a perfect system with no precision-recall tradeoff.

Key task #2 - Improve the precision and recall of the system
In automated systems this generally is the job of the engineering & data-science teams. In human-driven systems it’s generally the job of the operations managers. There are choices to be made here too:
Do you focus first on improving the precision part of the curve or the recall part of the curve (again, likely depends on your use case).
Perhaps there are subsegments that you want to get better at more urgently that others (e.g. is it more important to have high-precision, high-recall detection of hate speech in some languages vs others?)

Some ways to improve precision & recall
Refine your definitions of what’s good and bad. The performance of a detection system is fundamentally dependent upon the definition of, well, what you’re trying to detect. If the definition is wooly, then it’s hard for anything (human or machine) to separate “good” from “bad”. If you can make your definitions clear and objective, it’ll be easier (although not easy!) to build a high-recall, high-precision detection system.
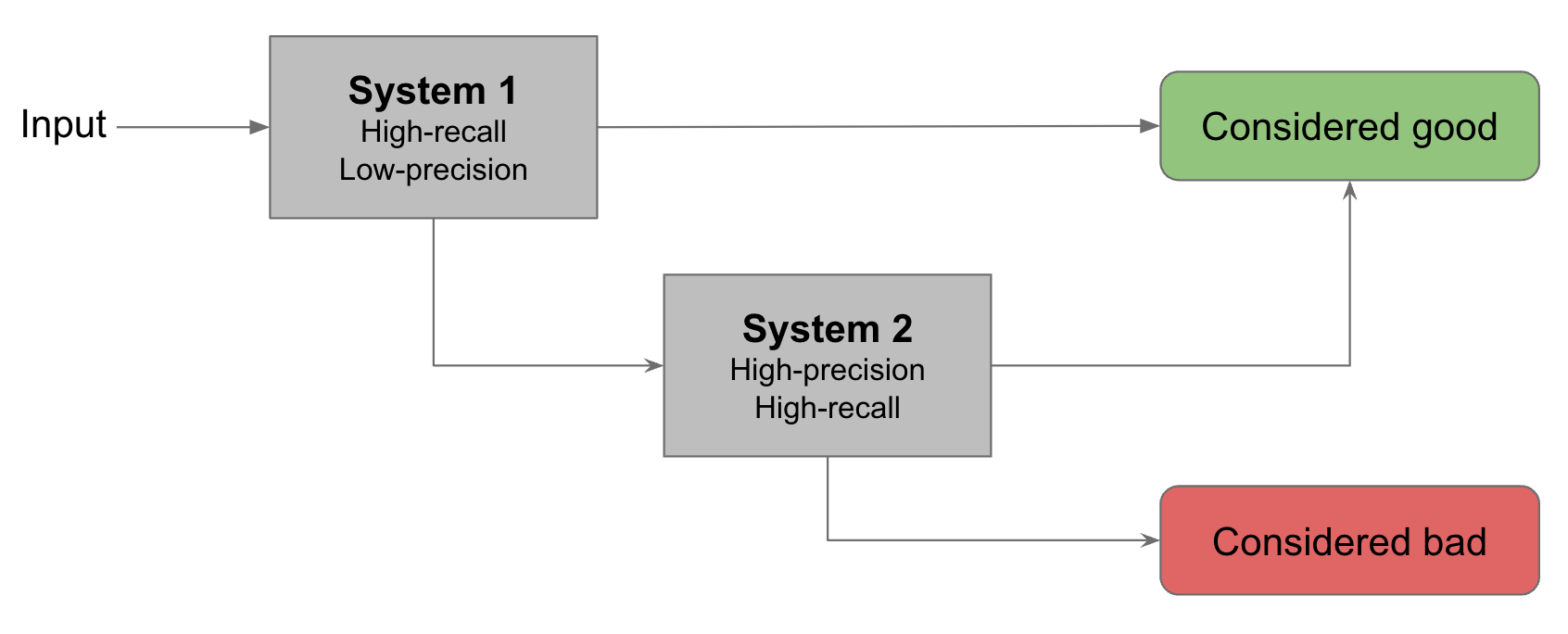
Chain systems together. A common way to improve the overall precision and recall of a system is to combine different detection methods that have different precision-recall properties. For example, a machine learning classifier has the benefit of being able to run all day, in milliseconds, on every piece of content (CPU cost allowing!) - something a human reviewer can’t do. So you could have your automation running at a lower threshold (lower-precision, higher-recall) to create a “shortlist” of “potentially bad” items which you then put in front of a well-trained human reviewer (high-recall, high-precision, but slow and expensive) to make the final decision.

Apply new technology. In content moderation, early systems were keyword based, but these are easily avoided by bad actors. Today, social media companies use machine learning that can weigh many more factors. Machine learning technology itself has improved dramatically over the last 5 years and continues to evolve.
I hope you now have a solid grasp of the basics of these important and widely applicable concepts. Getting this stuff clear in my own head was critical when I worked in online safety, but I’ve found them to be useful more generally at work, and in life more broadly.
I’m a product person, not a data-scientist or a machine-learning engineer — and there is a LOT more depth behind these topics than I’ve explained here - but this is the post I wish I’d been able to read when I realised these were things I needed to quickly understand — and I hope it’s been useful for you too!
Further reading:
Wikipedia: Confusion matrix
Wikipedia: Precision and Recall
Doug Steen: Precision-recall curves
Meta AI blog: Here's how we're using AI to help detect misinformation
Wikipedia: F-score